An Analysis of running different configurations of LevelDB

Abstract
In this report, I analyze the different configurations with which LevelDB can be run. I run the tests with the same benchmarks under different configurations of LevelDB. The benchmark I have used is the synthetic benchmark that comes with LevelDB out of the box.
I draw conclusions from the test results and find some predictable, and unpredictable results. I then use the configurations and results to understand and present how the different configurations of LevelDB affect the performance. Finally I give some suggestions on ideal configurations for different application workloads and requirements.
1 Introduction
Key-value stores are an important part of data intensive systems of today. They are preferred over relational SQL databases in applications that frequently change data schemas. LevelDB is an embedded Key-Value store designed for fast inserts, random lookups and range queries. Key-value stores generally use a Log-structured Merge Tree (LSM).

Writes in an LSM tree are made sequentially to an in memory structure called a memtable. The memtable is periodically made immutable and flushed into persistent storage in the form of an SSTable file. The LevelDB architecture [2] in Fig.1 shows that there are a total of 6 levels with the higher level L0 having the latest data and the lower levels L6 storing the old data. Levels exponentially grow in size as we go from higher to lower and obsolete data is removed in a process called compaction. An LSM tree is designed for fast inserts, random lookups and range queries. The LSM tree is the fundamental building block for LevelDB.
Different applications have different use cases and workloads, and thus it is important to configure LevelDB to suit the specific workload characteristics that it will face. For this reason, in this report, I analyze and understand the working of LevelDB in depth specifically to understand its different configurations and their effects on the performance. I ran benchmark tests with different configurations and options to see the performance impact of changing various options and also to get reasoning behind the performance variations. Changes are made in the benchmark file ./benchmarks/db bench.cc and the configuration file ./include/leveldb/options.h. I then look at some popular application types and try to categorize their workloads as lookup heavy range query heavy etc. Finally, I suggest LevelDB configurations to best serve these hypothetical application workloads.
2 Evaluation Methodology
I run benchmarking tests using the db bench benchmark [1] that comes with LevelDB. The tests are run with different configurations of LevelDB. I talk about the different configurations and the effects they have on the performance. Then I compare the expectations with the actual results while finding reasons for discrepancies, if any.
The tests are performed on a multitnant Linux machine running CentOS version 7 on a VMware hypervisor. The hardware hosting the system is a 28 core Intel Xeon E7–8890 CPU with 56 GB of memory and 64 MB of CPU cache. The hardware used for persistent storage was not available as the machine exports a 400 GB virtual storage disk space. I evaluate and find how much the performance deviates for LevelDB with different workloads. Then I suggest the configuration as either fit or unfit for the common hypothetical application workloads described below.
2.1 Data Logging application workload
This is a write heavy workload where extensive logs are be maintained. These logs are not frequently accessed and random lookups are rare. An example of this type of workload is a web-server logging all requests made to it.
2.2 Analytics application workload
Analytics application workloads usually consist of bulk loads, reads and range queries. The data that needs to be analyzed would be loaded into the database and then range queries are run on the data to be analyzed.
2.3 Random lookup workload
This kind of workload is usually seen with databases serving interactive applications. These workloads are generally well balanced between the read write ratio. Interactive applications are used by real users and thus response time is a big concern and some SLA must be maintained around it. These applications generally have random lookup queries and writes coming at a fairly consistent pace.
3 Evaluation
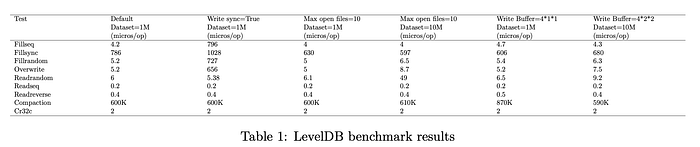
The default out of the box configuration for LevelDB uses the Snappy compression library for compression with a block size of 4KB. The default cache size is 8MB and a limit of 1000 on the maximum number of open files and a write buffer size of 4MB. This benchmark is run in order to get the performance of LevelDB with the default configuration.
All of the other tests are run by keeping the the behavior control options same and keeping Snappy Compression ON. Behavior controls are not changed because we are interested in looking at the performance variations with different configurations for this report and changing behavior would not affect performance. Snappy compression is always kept on because Snappy is a very fast compression library and there was no noticeable difference when turned off.
For the first test, I enable write sync mode. This mode makes sure that the data is flushed to persistent storage before returning success. There are no other changes to the configuration. Enabling sync ensures that no writes are lost in the event of a crash by explicitly calling fsync() after every write. In the real benchmark results, the async writes are many magnitudes slower. Synchronous writes are not as slow in comparison to default config run. This is because the synchronous writes calls fsync() frequently irrespective of whether write sync is turned on. Read operations are not affected by this configuration change.
For the second test, I set the max open files to 10. This is about 100x smaller than the default. Reducing the number of open files reduces the amount fo data available in memory to be read immediately. The first test I ran on this was with 1 million key value pairs. No major difference in performance was noticeable on this test as the file size was still small. For the next test with max open files set to 10, I ran the benchmark test with 10 million key value pairs to simulate a bigger database. This is where considerable difference is noticeable on reads. This is because LevelDB has to do many reads from the disk (which is slow) instead of memory. Range queries are not affected significantly as sequential disk reads are fast once the location of the first key in the range query is found. This can be seen as as a mode fit for resource constrained environments. The authors have suggested one open file for every 2MB of data [1].
Next, I increased the size of the write buffer to see how it affects write performance to the database. Increasing the size of the write buffer should see faster write operations. On a size of 1 million key value pairs, fill operations became slower with fillsync and fillrandom being the most affected. When the size was increased to 10 million, however, there was an improvement in write performance. I learnt that increasing the size of the buffer too much could cause L0 compaction to take longer causing the drop off in performance in a smaller size database.
4 Evaluation Results
The results of various evaluations performed are shown in Table 1. The results and their brief analysis shows that LevelDB configurations should be catered to best suit the host system and the type of workloads that LevelDB will experience.
For workloads that need strict write guarantees, enabling write sync would be an acceptable performance trade off. For all other workloads, I would recommend to not enable it, because fo the performance impact it has.
For analytical workloads, My recommendation would be to disable write sync, keep a large number for max open files and have a large write buffer because this kind of workload does a lot reads and bulk writes. Whereas, for logging type of workloads, it would be best to keep an average sized buffer size so as to not trigger a frequent flush to disk.
For real time application workloads, where maintaining a SLA is critical, the recommendation would be to keep the default configurations and modify the max open files according to the authors recommended budget.
5 Conclusion
In this report, I presented the performance characteristics of LevelDB running with different configurations. I presented how and why different configurations affect performance of LevelDB with different sized working sets as well as the trade offs. By understanding the needs of different hypothetical application workloads, I concluded that the right configuration can help in getting the most reliability and performance from LevelDB.
Finally, I suggest that applications with logging workloads should focus on speed of writes, analytical workloads should also turn off write sync to ensure fast writes and have a large write buffer. They should also consider increasing the number of maximum open files if the number of key value pairs in the database is big. Real time application workloads should focus on making sure that write and random read operations perform at an optimal speed.
References
[1] leveldb, https://github.com/google/leveldb
[2] Lanyue Lu, Thanumalayan Sankaranarayana Pillai, Hariha- ran Gopalakrishnan, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. 2017. WiscKey: Separating Keys from Values in SSD-Conscious Storage. ACM Trans. Storage 13, 1, Article 5 (March 2017), 28 pages. DOI:https://doi.org/10.1145/3033273
